探索MongoT(Atlas Search)
- 分解表(针对通过 MongoT 的约 9ms $search 聚合路径)
本地调试
样本数据
有趣示例 - 分面文本搜索
Lucene 索引策略及相对于 MongoD 索引的优势
向量搜索示例
本地 Grafana 监控
性能
Java 代码包
你能从 MongoT 学到什么?
总结
让我们来探索这个来自 MongoDB 的迷人且令人惊叹的 Java 项目——MongoT!
你可以在这里查看源代码:
git clone https://github.com/mongodb/mongot
[LOADING...]
MongoT 是一个围绕出色 Java 搜索引擎 Lucene 的封装。
Lucene 是一个强大的搜索工具包,基于倒排令牌索引结构构建,支持高级文本搜索功能,包括排名结果、自动补全、同义词、模糊匹配、高亮和分面——无论数据集大小,性能都极为出色。与 MongoDB 的原生查询引擎不同,它能够通过并行交集文档 ID 序数列表,并利用跳跃列表、序数压缩和文档频率排序等优化技术,高效地跨多个索引同时搜索。它还支持多种字段类型(整数、日期、关键字等)的索引,并且已经扩展到向量搜索,能够根据语义而非精确文本匹配进行相似性搜索。
将向量搜索添加到 MongoDB 显然是 MongoT 项目的核心目标,因为参与语义搜索领域非常重要。我认为除了向量搜索之外,它提供的其他功能也非常值得深入研究,因为 Lucene 的各种搜索类型极大地补充了 MongoDB 数据库自身基于 B 树的索引搜索功能。
让我们开始吧!
当你第一次看到 MongoT 项目的代码时,可能会因为其规模和复杂性而感到有些不知所措(我当时就是这样!)。
不过别担心!我们将逐步分解,并通过几个真实世界的查询示例来深入了解它的运作方式。最后,我希望你能对这个代码库感到熟悉,尝试 fork 它,并在调试、测试甚至修改代码的过程中找到乐趣。
如果你(像我一样)是视觉型学习者,可以边阅读边通过动画形式浏览代码包:https://luketn.com/mongot-app-tour/index.html
简单示例 - 文本搜索
让我们从一个真实的例子开始。以下是一个实际的 Atlas Search 查询:
db.image.aggregate([
{
$search: {
text: {
query: "Pizza",
path: "caption"
}
}
}
]);
结果返回:
[{
caption: 'Stacks of dominos pizza boxes with a pizza.',
url: 'http://images.cocodataset.org/train2017/000000371822.jpg',
hasPerson: false,
food: [
'pizza'
]
},...]
客户端应用程序通过其驱动程序将该查询作为 MongoDB 聚合命令发送给 MongoD(驱动程序从不直接连接到 MongoT——它只连接到 MongoD)。当 MongoD 到达 $search 阶段时,它会将公开的阶段重写为内部远程搜索阶段,构建一个 MongoT 搜索命令,并针对 MongoT 打开一个远程游标。
在 MongoT 内部,请求到达 gRPC 命令流,分发到 SearchCommand,解析搜索索引,创建游标,构建 Lucene 查询,执行初始 Lucene 搜索,物化 BSON 结果,并将第一批结果返回给 mongod。
如果游标尚未耗尽,则会保持打开状态,以便后续对 MongoD 游标的 getMore 操作可以依次从 MongoT 游标获取更多结果。
分解表(针对通过 MongoT 的约 9ms $search 聚合路径)
| 阶段 | 代码路径 | 指示耗时 | 命令耗时百分比(排除流式结果) | 含义 |
|---|---|---|---|---|
| 查询上下文 | SearchCommand.run | 17 us | 1.91% | 在解析请求前构建每个查询的执行上下文。 |
| 解析 BSON | SearchQuery.fromBson | 211 us | 23.71% | 将传入的 MongoT 搜索命令转换为 MongoT 查询模型对象。 |
| 索引查找 | SearchCommand.getIndexFromCatalog | 3 us | 0.34% | 在 MongoT 的内存目录中查找命名的搜索索引。 |
| 游标设置 | MongotCursorManagerImpl.newCursor, CursorFactory.createCursor, IndexCursorManagerImpl.createCursor | 46 us | 5.16% | 围绕索引阅读器和批处理生产者创建游标状态。 |
| 构建 Lucene 查询 | LuceneSearchQueryFactoryDistributor.createQuery, TextQueryFactory.createQuery | 37 us | 4.16% | 将 MongoT 的查询模型转换为 Lucene 查询。这是构造过程,而非执行过程。 |
| Lucene 收集命中 | MeteredLuceneSearchManager.initialSearch, LuceneOperatorSearchManager.initialSearch | 92 us | 10.34% | 执行初始 Lucene 文本搜索并返回第一个 TopDocs。 |
| 阅读器编排 | LuceneSearchIndexReader.query, LuceneSearchIndexReader.collectorQuery | 107 us | 12.02% | 处理阅读器簿记、存储源检查、分支调度以及围绕 Lucene 执行的锁定。 |
| 推进批次 | MongotCursor.getNextBatch, LuceneSearchBatchProducer.execute | 12 us | 1.35% | 为第一批次推进批处理生产者;后续的 getMore 可以使用 searchAfter。 |
| 物化 BSON | LuceneSearchBatchProducer.getSearchResultsFromIter, ProjectStage.project, MetaIdRetriever.getRootMetaId | 372 us | 41.80% | 将 Lucene 命中转换为 BSON 响应文档,包括存储源或 id/score 输出。 |
| 批次编排 | MongotCursorManagerImpl.getNextBatch, IndexCursorManagerImpl.getNextBatch | 16 us | 1.80% | 包装第一批次加载和游标耗尽检查。 |
| 响应文档 | SearchCommand.getBatch, MongotCursorBatch.toBson | 13 us | 1.46% | 构建命令响应包装器、游标文档和元数据变量。 |
| 编码 BSON | SearchCommand.getBatch, MongotCursorBatch.toBson | 1 us | 0.11% | 序列化在命令流上返回的响应负载。 |
| 流生命周期 | ServerCallHandler.onNext, ServerCallHandler.handleMessage, CommandManager | 8.078 ms outside command | N/A | gRPC 流在初始命令跨度之外的生命周期,包括响应观察器处理、客户端消费、清理以及同一流中的任何后续游标工作。 |
本地调试
接下来,让我们从源代码开始,在本地启动并运行 MongoT。我将在此演示中使用 IntelliJ 作为 IDE,但步骤应该与任何 IDE 类似。
请按以下步骤操作:
- 首先,你需要在 IntelliJ 中安装 JetBrains IntelliJ Bazel 插件才能处理该项目:https://plugins.jetbrains.com/plugin/22977-bazel
- 克隆仓库并在 IntelliJ 中打开(IntelliJ 会自动识别 Bazel 项目,并配置一个映射到 Bazel 配置的 IntelliJ 项目)
git clone https://github.com/mongodb/mongot
cd mongot
idea .
- 通过将以下更改添加到
community-quick-start/docker-compose.yml文件中的mongot-local容器来启用调试:
mongot-local:
...
command:
- /mongot-community/mongot
- --jvm-flags
- "-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005"
- --config=/mongot-community/config.default.yml
mongot-local:
...
ports:
...
- 5005:5005 # Debug port
[LOADING...]
这将允许我们通过 5005 调试器端口连接到本地构建的 mongot 代码并进行调试。
- 在项目根目录的 shell 中运行本地构建的 mongot 代码:
make docker.up MODE=local
构建完成且容器运行后,我们可以将调试器附加到 5005 端口。
- 创建一个远程 JVM 运行配置:
[LOADING...]
[LOADING...]
- 运行新的 MongoT Container 运行配置,你会看到 IntelliJ 现在正在调试源代码:
[LOADING...]
你可以使用 Compass 连接到 MongoDB:
[LOADING...]
配置连接时,需要将 TLS 设置指向 community-quick-start/tls 目录中的 ca.pem 和 client-combined.pem 文件:
[LOADING...]
样本数据
你可以在 MongoDB 官方页面找到 Atlas 的优秀示例数据库:https://www.mongodb.com/docs/atlas/sample-data
当我们运行上述社区快速启动时,本地实例已经预填充了其中一些示例数据集。
在本文的其余部分,我将使用自己创建的小例子,你可以在这里找到数据和索引映射:https://github.com/luketn/atlas-search-coco-dataset
(这是一个针对流行 COCO 图像数据集的分面索引。)
如果你想深入了解相关代码,这里有一篇教程:https://github.com/luketn/atlas-search-coco
https://tech-blog.luketn.com/java-faceted-full-text-search-api-using-mongodb-atlas-search
以下是 Atlas Search Coco 示例项目,通过本地调试的 MongoT 提供来自 Coco 图像数据集的查询数据:
[LOADING...]
以下是通过 Compass 在本地 MongoT 中构建的索引:
[LOADING...]
如果你探索这个应用,你会在撰写本文时发现一些有趣的事情,比如使用本地 LLM、向量嵌入和查询进行实验。
创建一些示例数据库(或者实际数据库!),创建 Atlas Search 索引,并在本地执行查询。在代码中设置断点,尽情探索,看看它们是如何协同工作的。
有趣示例 - 分面文本搜索
让我们更深入一些,执行一个分面搜索示例。
以下是一个 Atlas Search 查询,匹配标题中包含“frisbee”且动物类别为“dog”的图片。我们请求对结果集的两个分面进行计数,以便查看匹配结果中有多少也包含“sports”类别。
在 MongoDB Compass 的 shell 中运行以下命令,并在代码的 TextQueryFactory.createQuery 处设置断点。
db.image.aggregate([
{
$search: {
facet: {
operator: {
compound: {
filter: [
{
text: {
path: "caption",
query: "frisbee"
}
},
{
equals: {
path: "animal",
value: "dog"
}
}
]
}
},
facets: {
animal: {
type: "string",
path: "animal",
numBuckets: 10
},
sports: {
type: "string",
path: "sports",
numBuckets: 10
}
}
},
count: {
type: "total"
}
}
},
{
$facet: {
docs: [],
meta: [
{
$replaceWith: "$$SEARCH_META"
},
{
$limit: 1
}
]
}
}
]);
[LOADING...]
你可以逐步执行,并看到它创建 Lucene 查询对象实例,例如,从 Atlas Search 分面复合子句构建的 TermQuery($type:string/caption:frisbee)。
继续逐步执行,最终你会到达 LuceneFacetCollectorSearchManager.initialSearch:
[LOADING...]
在这里,你可以看到完全组合的 BooleanQuery,将字符串类型的 TermQuery(针对 frisbee)与令牌类型的 TermQuery(针对 dog)结合。
这对于学习 Lucene 查询的 Java 库 API(有些晦涩)来说很有趣。
Lucene 返回的结果包括匹配的文档和分面:
[LOADING...]
你可以继续深入探索,了解封装器如何从 Lucene 索引中整理文档的各种方式。
你会注意到一些有趣的事情,比如 Lucene 索引中的 _id 是整数。这是 Lucene 工作方式的核心,稍后我会解释原因:
[LOADING...]
[LOADING...]
MongoDB 的 ObjectID(或你使用的任何类型)_id 会作为元数据存储,并根据需要作为结果集的一部分返回:
com.xgen.mongot.index.lucene.query.util.MetaIdRetriever#getRootMetaId
最终,MongoDB 会显示如下结果:
{
docs: [
{
_id: 27617, // 在 Atlas Search Coco 示例数据中,我使用了整数 ID
caption: 'A dog relaxes on the green grass as he holds a yellow frisbee.',
url:'http://images.cocodataset.org/train2017/000000027617.jpg',
hasPerson: false,
animal: [
'dog'
],
kitchen: [
'bowl'
]
},
... 365 more items
],
meta: [
{
count: {
total: 366
},
facet: {
sports: {
buckets: [
{
_id: 'frisbee',
count: 364
},
{
_id: 'sports ball',
count: 4
},
{
_id: 'baseball glove',
count: 1
}
]
},
animal: {
buckets: [
{
_id: 'dog',
count: 366
}
]
}
}
}
]
```## Lucene 索引策略及相对于 MongoD 索引的优势
让我们暂时从细节中抽身,思考一下:为什么还要使用 Atlas Search?
对我而言,有三个令人信服的理由:
* 高级文本搜索
* 多索引搜索并合并结果
* 向量搜索
我一直是 Lucene 的狂热粉丝。
它是一个出色的搜索工具包,我曾将其作为嵌入式 Java 库在应用程序中使用,也在诸如优秀的 Elasticsearch(及其开源分支 OpenSearch)和 Solr 等服务中使用过。
性能出色,查询语法直观(一旦习惯),索引方法极其高效且灵活。随着向量搜索的加入,我们现在拥有了完整的文本搜索和高级并行索引,与 MongoDB 自身的搜索完美互补。
##### MongoDB 内置搜索的现状
当字段和查询模式定义良好时,MongoDB 的原生索引和查询引擎非常快速且强大。
在设计高效的内置索引以获得出色性能时,你可以:
* 优化集合和文档设计
* 使用 ESR 规则优化索引
* 调整索引数量以获得良好的读写性能
* 使用 explain 计划和实际实验优化查询
然而,在某些搜索场景下,MongoDB 显得不足。这时 Lucene 登场,以增强或解决这些用例:
#### 高级文本搜索
MongoDB 提供了一些基本的文本搜索能力,使用 $text 或 $regex 查询。这些对于小型数据集上的简单搜索尚可,但当数据集增大或查询变得更复杂时(尤其是 $regex),通常极其缓慢。
相比之下,Lucene 能够以 Google/Amazon 搜索框的风格执行高级文本搜索,支持排序结果、自动补全、同义词、模糊匹配、高亮和分面。不仅如此,它还能以出色性能完成这些操作,几乎不受数据量大小影响,这要归功于其“倒排”令牌索引结构。
这是一个非常深的话题,我不会在此全部覆盖,但 Lucene 文档和 MongoDB 文档中都有很好的参考资料:<https://lucene.apache.org/core> 和 <https://www.mongodb.com/atlas/search>
#### 多索引搜索并合并结果
MongoDB 无法进行多索引搜索。MongoDB 每次查询只使用一个索引,如果需要进一步过滤,则直接在文档上进行。MongoDB 对多个索引字段的查询大致如下:
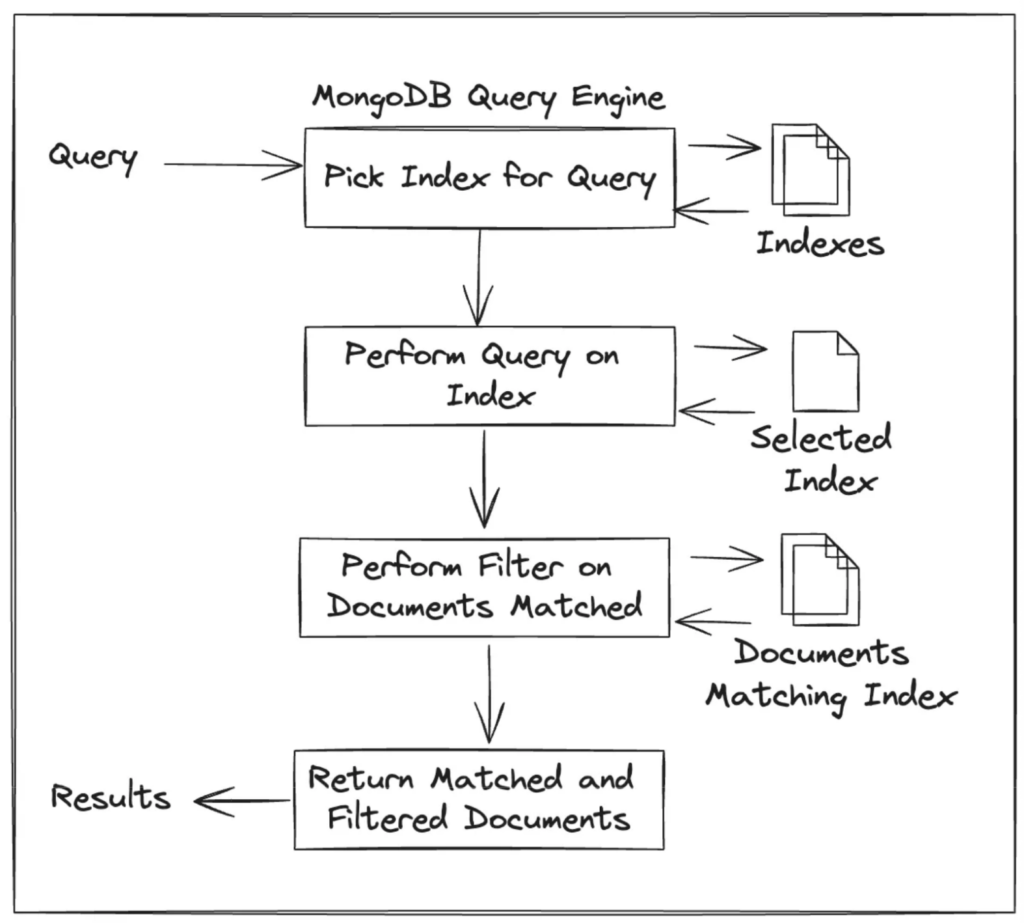
(对 MongoDB 查询引擎的粗略简化)
即,查询规划器选择一个索引并使用它。
相比之下,Lucene 可以高效地在多个索引上执行搜索,并返回结果的交集。
Lucene 中的每个文档都被分配一个序数 ID —— docid(0, 1, 2……)。
在典型的文本字段索引中,Lucene 将文本分析为词条。它将词条存储在词条字典中,每个词条指向一个倒排列表:一个紧凑、排序的 Lucene 内部文档 ID 列表,这些文档包含该词条。
你也可以为不需要文本提取的字段(如整数、浮点数、日期、枚举和关键字)创建更简单的 1-1 索引。
你可以将 Lucene 索引视为一组从词条 ID 到文档 ID 列表的映射。
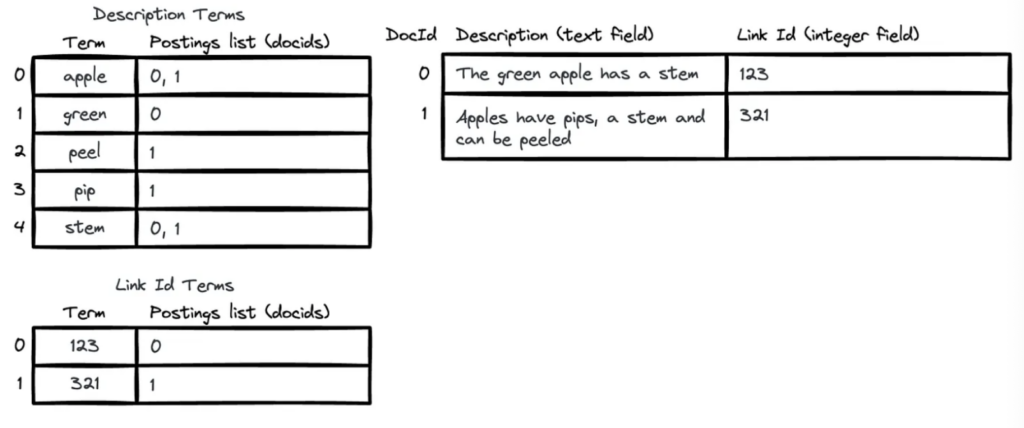
由于数据的基本结构和排序顺序以及序数索引,加上一些优化技术(如跳表、序数压缩、文档频率排序),Lucene 在执行索引交集时非常高效。
MongoT 创建与 MongoDB 文档匹配的 Lucene 文档,将所有 Atlas Search 索引字段映射到 Lucene 文档中。
根据你在 Atlas Search 字段映射中为每个字段选择的选项,MongoT 会在 Lucene 文档中以不同方式存储 MongoDB 文档的值。它可能使用多种 Lucene 文档字段类型存储单个值,以支持过滤、排序和分面:
<https://lucene.apache.org/core/9_10_0/core/org/apache/lucene/index/package-summary.html#field_types>

因此,花些时间调优 Atlas Search 索引字段映射,确保只选择真正需要的选项,可能是值得的。字段映射和类型越大越复杂,性能就越差,资源需求也越重。
正如我们在“有趣示例”中看到的,MongoDB 文档的 _id(通常是 ObjectId)会与 Lucene 索引一起存储,并映射到/从序数文档 ID 映射。这保持了与 MongoD 数据的连接,同时获得了 Lucene 序数 ID 数据结构的性能优势。
#### 向量搜索
Lucene 中的向量索引能够高效地找到与搜索词最接近的语义相似匹配。
Atlas 文本搜索可以通过词法文本匹配技术在“circular”和“circle”之间找到匹配。
而基于向量的语义搜索则可以从“circular”匹配到“round”。
这非常惊人,用户已开始期望搜索引擎理解他们的意图,而不仅仅是他们所写的内容。因此,向量搜索正在成为一项必备功能。
它通过使用一个数字数组(嵌入)并在多个维度上计算距离的算法实现。老实说,这里的数学有点超出我的理解范围,但我可以使用本地或基于 API 的端点将一些文本生成嵌入向量。
我非常喜欢的一点是同时拥有词法搜索和向量搜索支持,可以结合两者,看到查询的词法和语义意义匹配。我认为这使得搜索引擎超级强大,结果既逻辑又准确。
向量的主要缺点是计算搜索词嵌入所需的时间,以及为大量文本语料生成嵌入的成本。
MongoT 令人兴奋的能力之一是自动嵌入,即能够插入一个向量嵌入引擎(目前支持 Voyage AI)。当启用向量引擎时,向量会在后台自动计算(当你插入和更新数据时),你可以向 $vectorSearch 提供查询文本而不是 queryVector 数组,此时 MongoT 也会自动对查询词进行嵌入。这太酷了,我认为未来所有向量解决方案都将这样工作(即数字数组是一个不可见的抽象实现细节)。
#### 延伸阅读
Lucene 及其索引和查询能力远不止于此。
如果你想更深入了解 Lucene 索引的工作原理,强烈推荐这个:
[What is in a Lucene index? Adrien Grand, Software Engineer, Elasticsearch](https://www.youtube.com/embed/T5RmMNDR5XI?si=5MXcHGSkBduIZGOL)
<https://www.slideshare.net/lucenerevolution/what-is-inaluceneagrandfinal>
## 向量搜索示例
让我们设置向量搜索!
开始之前,你需要注册 Voyage API 并创建 API 密钥:
<https://dashboard.voyageai.com/organization/api-keys>
**警告** - 你需要支付方式来计算向量,所以这*可能*会花费实际金钱,尽管在我的测试中我完全在免费配额内。
然后重启 MongoT。
接下来你需要更新 MongoT 配置文件(mongot-dev.yml),添加以下几个新字段:
embedding: queryKeyFile: "/Users/luketn/code/personal/mongot/voyage-api-key" indexingKeyFile: "/Users/luketn/code/personal/mongot/voyage-api-key" providerEndpoint: "https://api.voyageai.com/v1/embeddings" isAutoEmbeddingViewWriter: true
然后重启 MongoT。
你应该会在日志中看到:
CommunityMongotBootstrapper...Initialized auto-embedding with 4 model(s)
启用 Voyage API 后,你可以像这样创建向量搜索索引:
db.image.createSearchIndex({ name: "caption_auto_embed", type: "vectorSearch", definition: { fields: [ { type: "autoEmbed", path: "caption", model: "voyage-4", modality: "text" } ] } });
MongoT 会自动批量调用 API,使用 voyage-4 模型为 caption 字段计算嵌入,并将它们单独存储在内部管理的嵌入集合中,这很好,因为它不会用索引数据污染 MongoDB 文档!
(尽管我可能会说 Lucene 索引文件可能是一个更好的抽象)
然后你可以使用简单的文本查询参数执行搜索:
db.image.aggregate([{$vectorSearch: { index: "caption_auto_embed", query: "circular flying", path: "caption", numCandidates: 10, limit: 10 }}]);
在幕后,MongoT 为查询文本“circular flying”计算嵌入,使用 Voyage API 将其语义含义计算为一个浮点数数组,然后使用 Lucene 在索引中查找语义上最接近的匹配。
你可以在 EmbeddingServiceManager.embed() 上设置断点,查看查询路径的工作原理:
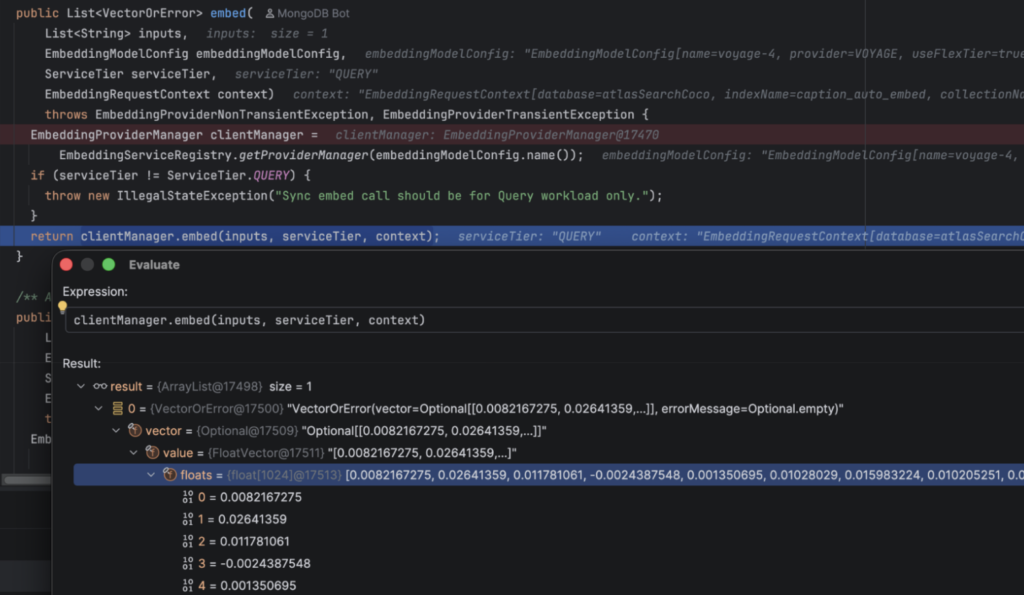
太酷了。显然这有实际的经济成本,但这是终极的便利性。
如果你选择了自行计算嵌入的替代路径,可能会使用本地模型,将向量存储在 MongoDB 文档中并进行索引,你会理解这条路径的价值。我在写这篇文章时就使用 LM Studio 在本地做了这件事——这是一整套事情。我不会在这里详细介绍,但如果你感兴趣,欢迎提出问题,或者我可以在另一篇文章中介绍。
在尝试了使用 LM Studio 的手动向量计算和 Voyage API 之后,我推荐使用 Voyage API :)。
话虽如此,深入向量搜索需要你清楚了解成本——包括财务成本以及时间和资源成本。这不是免费就能得到的。
## 本地 Grafana 监控
如果你非常有冒险精神,你可以配置 MongoT 使用 OpenTelemetry 输出性能追踪和指标,使用 Jaeger 收集追踪数据,Prometheus 收集指标,并用 Grafana 可视化。
我不会在这里写完整指南,但我的 MongoT 分支中有一个辅助脚本,用于启动 Jaeger、Prometheus 和 Grafana:
<https://github.com/luketn/mongot/blob/main/local-monitoring.sh>
(该脚本还会写入连接它们的 MongoT 配置)
以及一些说明:
<https://github.com/luketn/mongot/blob/main/LOCAL-RUN.md>
## 性能
MongoT 的性能令人难以置信。我在 Grafana 中添加了一个小仪表盘:
<https://github.com/luketn/mongot/blob/main/local-grafana-mongot-dashboard.json>
并对 MongoT 代码稍作调整,为系统中搜索命令的分布输出更好的桶:
<https://github.com/luketn/mongot/pull/1/changes>
然后运行了一个 K6 负载测试脚本,看看 MongoT 在整体搜索中的表现如何。如你所见,MongoT \*(Lucene) 在 Atlas Search 查询的整体性能中发挥着重要作用。
以下展示了 Java Atlas Search API 的端到端性能。
正如 MongoT 性能仪表盘在 Grafana 中所展示的:
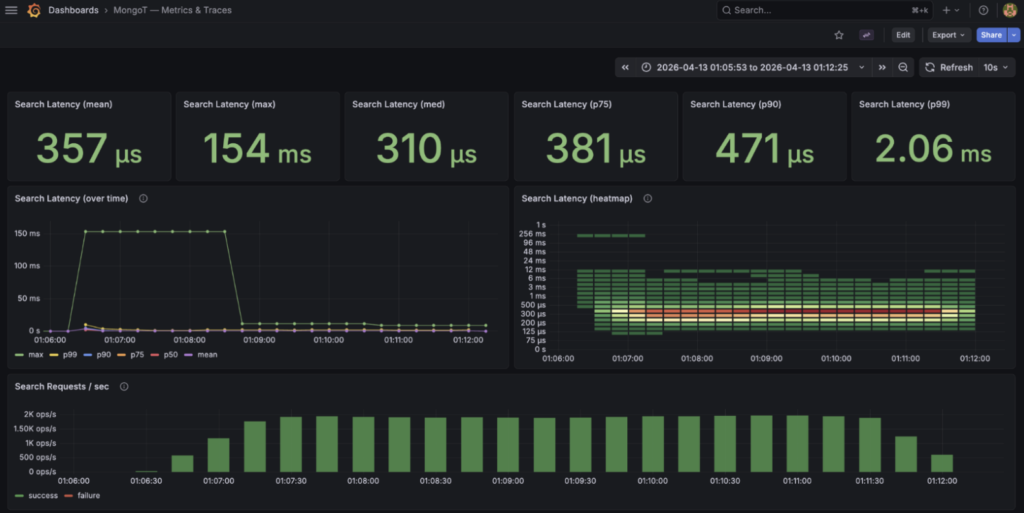
以及从 K6 客户端看到的结果:
k6 run -e K6_VUS=25 -e K6_DURATION=5m k6.js
█ TOTAL RESULTS HTTP http_req_duration: avg=12.8ms, min=2.4ms, med=12.3ms, max=208.4ms p(90)=17.4ms p(95)=18.9ms http_reqs: 574,519 1,914.977657/s CUSTOM search_docs_returned: avg=4.4, min=0, med=5, max=5, p(90)=5, p(95)=5 EXECUTION vus: 25 NETWORK data_received: 2.7 GB 9.1 MB/s data_sent: 84 MB 281 kB/s
(在 M4 MacBook Pro 上运行)
这意味着什么呢?根据 K6 客户端测量的 Java HTTP Atlas Search API 调用的完整往返中位数响应时间为 12.8ms(使用了 COCO 图像数据集中的多种数据场景)。
如果我为每个请求添加一些追踪,我可以看到 Java 相对于 MongoT->MongoD 端到端查询命令的开销:
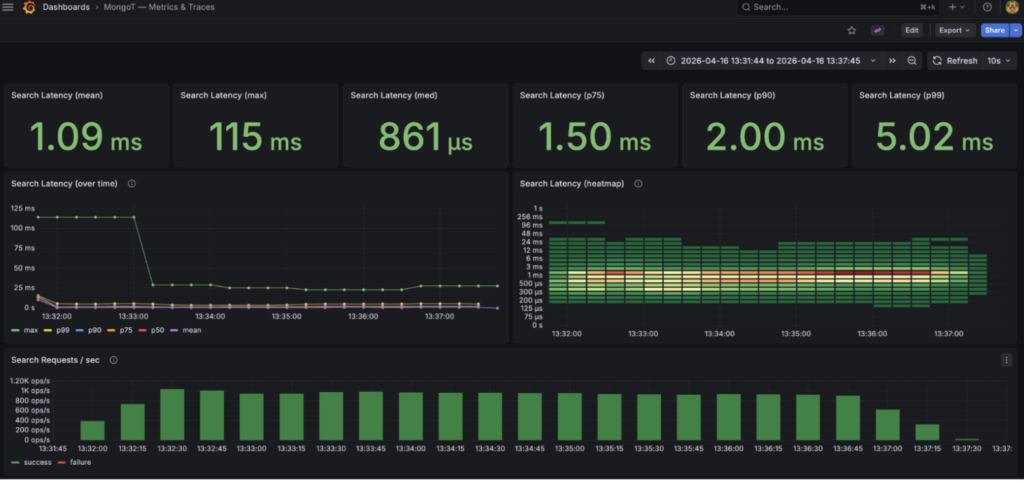
k6 run -e K6_VUS=25 -e K6_DURATION=5m k6.js CUSTOM docs_returned: avg=4.42, min=0, med=5, max=5, p(90)=5, p(95)=5 http_time_ms: avg=25.6, min=7.4, med=25.5, max=83.238, p(90)=31.5 p(95)=33.7 java_time_ms: avg=2.9, min=0.2, med=3.1, max=46.8, p(90)=3.6, p(95)=3.9 mongodb_time_ms: avg=7.2, min=2.0 med=6.8, max=48.7, p(90)=9.85 p(95)=11.0 requests: 291719 972.301245/s
我承认在这个兔子洞里越陷越深,花了更多时间进一步扩展默认发射的追踪中的 span 数量。我在自己的 fork 上创建了一个 MongoT 分支,并添加了大量详细的追踪:
<https://github.com/luketn/mongot/pull/2/changes>
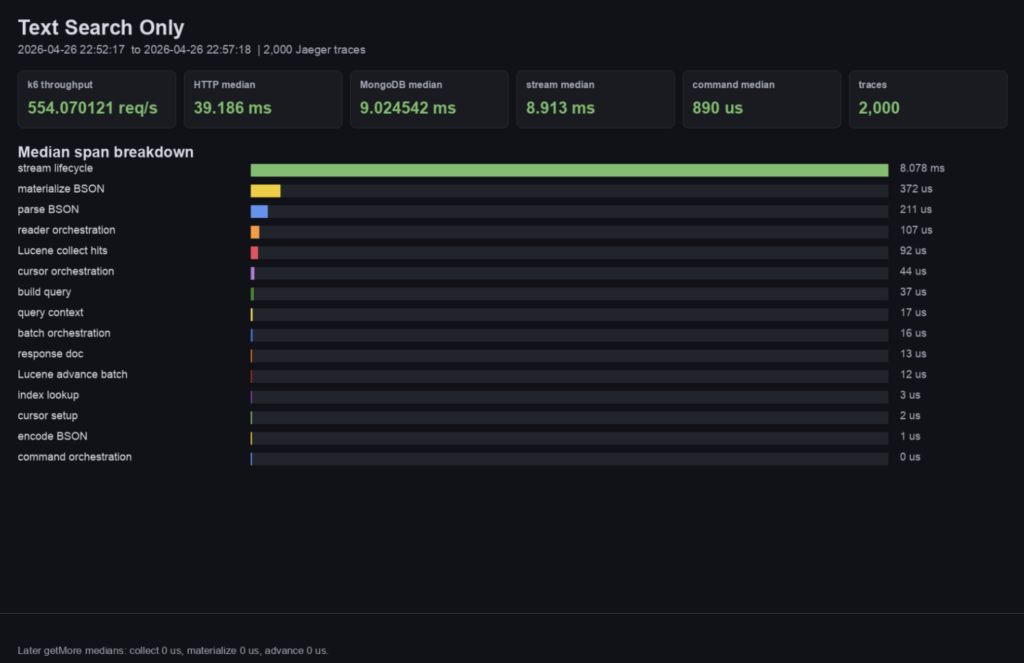
通过这些追踪,你可以看到整个系统中实际 Lucene 索引查询部分只占查询总时间的一小部分。
并且在 K6 负载客户端运行期间:
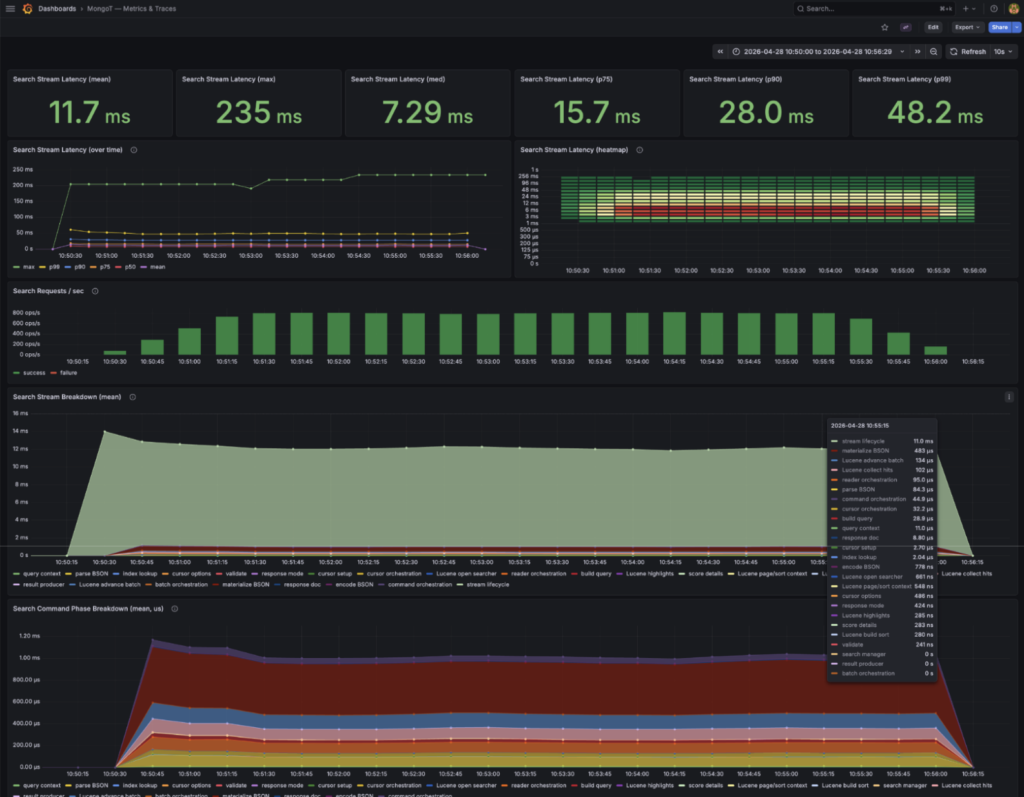
(注意时间因额外追踪而变慢)
这意味着什么呢?我认为这个项目最有趣的一点之一就是 Lucene 本身。
如果你查看 MongoT 内部的时间分解,只有一小部分时间用于执行实际的 Lucene 索引搜索。其余时间用于解析 BSON、协调游标以及其他与搜索无关的活动。
总体而言,Atlas Search 的整体性能非常出色,两者结合构成了一台稳定可靠的高性能搜索引擎,在事务数据和搜索索引之间紧密耦合(以好的方式!)。
我非常喜欢可视化的性能表示,并且能够提取追踪信息:
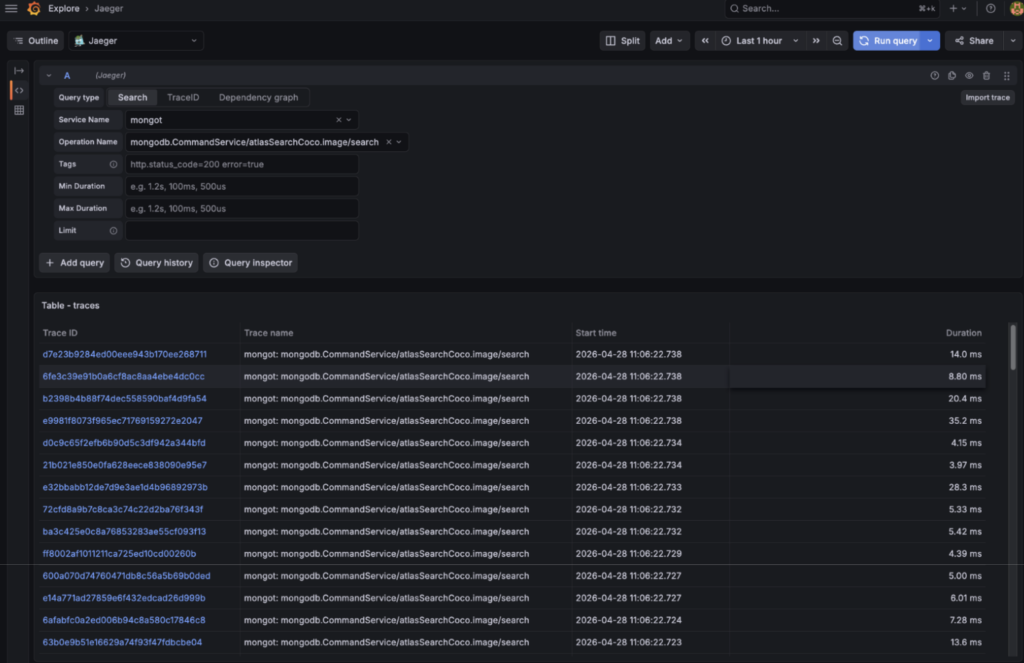
然后逐步查看搜索追踪中的 span:
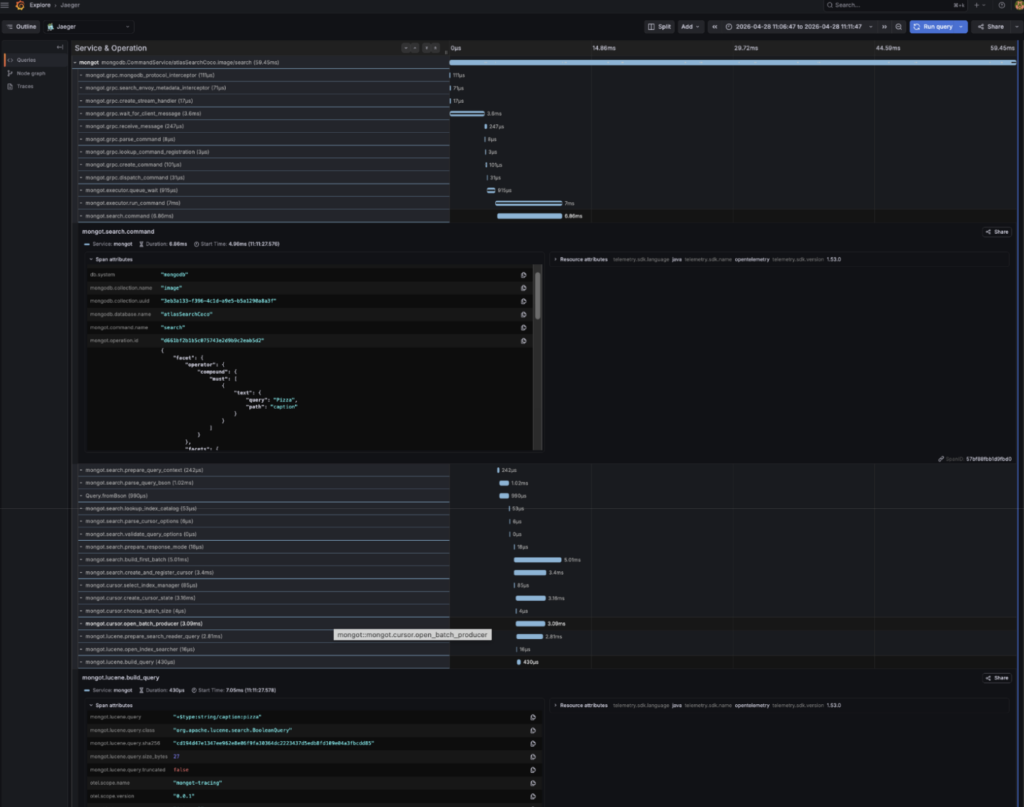
这确实帮助我理解代码及其工作原理。当然,额外的追踪会严重影响性能,但如果你愿意,可以查看该分支并尝试使用 Grafana 仪表盘!## Java 代码包
以下是 MongoT 项目的主要包及其相互交互关系:
| 包名 | 描述 | 关联的主要包 |
|-------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| com.xgen.mongot.community | 社区版入口点及顶层装配/启动引导连接。 | com.xgen.mongot.util, com.xgen.mongot.config, com.xgen.mongot.logging |
| com.xgen.mongot.index | 核心搜索/向量引擎:索引定义、数据摄取、Lucene 集成、查询执行、结果整形以及索引状态/元数据。 | com.xgen.mongot.util, com.xgen.mongot.featureflag, com.xgen.mongot.metrics, com.xgen.mongot.cursor, com.xgen.mongot.embedding, com.xgen.mongot.monitor, com.xgen.mongot.trace, com.xgen.mongot.server, com.xgen.proto, com.xgen.mongot.blobstore, com.xgen.mongot.config, com.xgen.mongot.logging |
| com.xgen.mongot.replication | MongoDB 复制管道,包括初始同步、稳态变更流处理、持久性以及索引工作调度。 | com.xgen.mongot.util, com.xgen.mongot.index, com.xgen.mongot.metrics, com.xgen.mongot.embedding, com.xgen.mongot.logging, com.xgen.mongot.featureflag, com.xgen.mongot.catalog, com.xgen.mongot.cursor, com.xgen.mongot.monitor |
| com.xgen.mongot.server | 外部服务器接口:gRPC/命令处理、协议适配、请求路由和流式响应。 | com.xgen.mongot.util, com.xgen.mongot.index, com.xgen.mongot.cursor, com.xgen.mongot.config, com.xgen.mongot.catalogservice, com.xgen.mongot.catalog, com.xgen.mongot.embedding, com.xgen.mongot.metrics, com.xgen.mongot.featureflag, com.xgen.mongot.trace |
| com.xgen.mongot.embedding | 嵌入提供者集成、请求上下文、自动嵌入辅助工具以及向量工作流的物化视图支持。 | com.xgen.mongot.util, com.xgen.mongot.index, com.xgen.mongot.metrics, com.xgen.mongot.replication |
| com.xgen.mongot.config | MongoT 子系统的配置模型、验证、提供者、变更计划及配置管理工作流。 | com.xgen.mongot.util, com.xgen.mongot.index, com.xgen.mongot.replication, com.xgen.mongot.featureflag, com.xgen.mongot.metrics, com.xgen.mongot.catalog, com.xgen.mongot.catalogservice, com.xgen.mongot.embedding, com.xgen.mongot.server, com.xgen.mongot.monitor, com.xgen.mongot.cursor, com.xgen.mongot.lifecycle, com.xgen.mongot.logging |
| com.xgen.mongot.cursor | 用于分页搜索结果/getMore 流程的游标领域模型、管理器、批处理及序列化。 | com.xgen.mongot.index, com.xgen.mongot.util, com.xgen.mongot.trace, com.xgen.mongot.catalog, com.xgen.mongot.metrics |
| com.xgen.mongot.catalogservice| 元数据服务层,为权威索引定义、每服务器索引统计以及存储在内部元数据库中的服务器心跳提供支持。 | com.xgen.mongot.util, com.xgen.mongot.index, com.xgen.mongot.replication |
| com.xgen.mongot.catalog | 本地索引目录的抽象与实现,用于解析/搜索索引状态。 | com.xgen.mongot.index |
| com.xgen.mongot.blobstore | 这是有趣的部分;看起来可能是社区版未来的路线图特性,或者是供我们扩展的内容。目前尚未找到如何配置它以将索引快照存储到 AWS S3 等 blob 存储中。 | com.xgen.mongot.util |
| com.xgen.mongot.featureflag | 静态和动态特性标志定义,以及运行时标志注册表/配置。其中包含一些有趣的标志,例如:`ENABLE_10K_BUCKET_LIMIT`。不知道你是否有同感,但我确实遇到过当前 [1000](https://www.mongodb.com/docs/atlas/atlas-search/operators-collectors/facet/#options) 分桶限制不够用的情况! | com.xgen.mongot.util, com.xgen.mongot.index |
| com.xgen.mongot.lifecycle | 启动/关闭生命周期协调,特别是围绕索引生命周期管理。 | com.xgen.mongot.index, com.xgen.mongot.util, com.xgen.mongot.replication, com.xgen.mongot.catalog, com.xgen.mongot.metrics, com.xgen.mongot.blobstore, com.xgen.mongot.monitor |
| com.xgen.mongot.logging | 结构化日志辅助工具及 JSON 日志格式自定义。 | 无 |
| com.xgen.mongot.metrics | 指标抽象以及全时诊断数据捕获(FTDC)收集/报告基础设施。 | com.xgen.mongot.util, com.xgen.mongot.index |
| com.xgen.mongot.monitor | 磁盘和复制状态监控、门控及滞回控制,用于在压力下保护服务行为。 | com.xgen.mongot.util, com.xgen.mongot.config, com.xgen.mongot.metrics |
| com.xgen.mongot.trace | OpenTelemetry 追踪辅助工具、导出器、采样开关及追踪解析工具。 | 无 |
| com.xgen.mongot.util | MongoT 通用的基础代码:BSON/proto 转换、并发辅助工具、集合、版本控制及通用工具。 | com.xgen.proto, com.xgen.mongot.metrics, com.xgen.mongot.logging |
| com.xgen.proto | 支持 BSON 的 protobuf 运行时,以及针对 BSON 能力 protobuf 消息的代码生成插件。 | 无 |
深入分析最重要的包之一——`com.xgen.mongot.index`:
| 包名 | 描述 | 关联的主要包 |
|-----------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| com.xgen.mongot.index.lucene | 最大的执行层:基于 Lucene 的索引、搜索、高亮、结果整形、提交管理以及搜索器编排。 | com.xgen.mongot.index.query, com.xgen.mongot.index.definition, com.xgen.mongot.index.analyzer, com.xgen.mongot.index.path, com.xgen.mongot.index.ingestion, com.xgen.mongot.index.version, com.xgen.mongot.index.synonym, com.xgen.mongot.index.status, com.xgen.mongot.index.blobstore |
| com.xgen.mongot.index.query | 查询 AST、操作符、收集器、分页、评分整形以及将请求语义转换为 Lucene 执行。 | com.xgen.mongot.index.path, com.xgen.mongot.index.definition, com.xgen.mongot.index.lucene |
| com.xgen.mongot.index.definition | 搜索、向量和视图索引的核心模式模型,包括字段定义、选项及验证逻辑。 | com.xgen.mongot.index.version, com.xgen.mongot.index.analyzer, com.xgen.mongot.index.query, com.xgen.mongot.index.lucene, com.xgen.mongot.index.path |
| com.xgen.mongot.index.ingestion | BSON 文档处理、字段提取及摄取时转换,为 Lucene 索引提供输入。 | com.xgen.mongot.index.definition, com.xgen.mongot.index.lucene |
| com.xgen.mongot.index.analyzer | 分析器构建器、提供者、工厂以及索引定义和查询时分析的特定语言分词管道。 | com.xgen.mongot.index.definition, com.xgen.mongot.index.lucene, com.xgen.mongot.index.path, com.xgen.mongot.index.query |
| com.xgen.mongot.index.autoembedding | 自动嵌入和物化视图索引辅助工具,用于派生生成字段并协调面向嵌入的索引元数据。 | com.xgen.mongot.index.definition, com.xgen.mongot.index.mongodb, com.xgen.mongot.index.status, com.xgen.mongot.index.version, com.xgen.mongot.index.analyzer, com.xgen.mongot.index.query |
| com.xgen.mongot.index.blobstore | 用于通过 blob 存储持久化和恢复索引状态的快照钩子。 | com.xgen.mongot.index.version |
| com.xgen.mongot.index.mongodb | 面向 MongoDB 的窄接口辅助工具,用于物化视图写入以及索引相关指标/状态传播。 | com.xgen.mongot.index.lucene, com.xgen.mongot.index.status, com.xgen.mongot.index.version |
| com.xgen.mongot.index.path | 共享路径抽象,用于跨模式与查询代码解析和遍历点分隔字段路径。 | 无 |
| com.xgen.mongot.index.status | 索引和同义词状态枚举/模型,用于暴露生命周期和就绪状态。 | 无 |
| com.xgen.mongot.index.synonym | 同义词映射模型、注册表和状态跟踪,集成 Lucene 查询行为。 | com.xgen.mongot.index.status, com.xgen.mongot.index.definition |
| com.xgen.mongot.index.version | 索引格式/版本标识符、生成元数据及兼容性/能力检查。 | 无 |
参考:<https://github.com/luketn/mongot/blob/main/MONGOT_PACKAGE_TOUR.md>
## 那么你能从 MongoT 中学到什么?
对我而言,这是一个出色的例子,展示了优秀数据库公司 MongoDB 如何构建一个生产级的搜索引擎配套应用。
其中有多个值得学习的方面:
* 如何以稳健可靠的方式执行变更流,将数据同步到任何外部系统(Lucene 就是一个很好的例子)
* 如何用 Java 管理 Lucene 索引并进行搜索
* 如何构建一个可扩展的 Java 服务,使其在生产环境中能增长到巨大规模
* 如何无缝地执行基于向量的语义搜索
在此介绍中,我们没有对这些主题进行深入探讨,但希望它能为你提供一个快速指南,让你入门,并启发你去探索其中的宝藏。
## 结束语
过去几周,我一直在探索该代码库,并实际操作 Atlas Search(包括词法搜索和语义搜索)。这非常有趣,我也学到了很多。
希望你在自行探索和尝试时也能大有收获。
搜索愉快!
文章 [探索 MongoT(Atlas Search)](https://foojay.io/today/exploring-mongot-atlas-search/) 首发于 [foojay](https://foojay.io)。